
Agentis Memory — Redis-Compatible Store with Built-in Vector Search and Local Embeddings
and another LLM's fantastic features.. again...

These days, nobody’s impressed by yet another agent, another optimization, another model, or another piece of AI infrastructure. It’s all business as usual. But there’s a funny gap between reading on Twitter that “we built agent X and it optimized our processes by 300,000%” and actually digging into what people mean by “agent.” Dig a little — and half the time, their “agent” is a single skill with one prompt.
Building real agents is not a trivial task. Just look at the leaked Claude CLI source code — it’s not a CLI, it’s an entire business logic infrastructure wrapped around an LLM. I’d compare agent development to building typical backend components. The analogy goes like this: if you’re building a canonical backend service, you need a database. If you’re building a Web3 service, you need a blockchain. But the database or blockchain handles maybe 50% of the actual logic at most. All the real magic happens in the backend itself. Same with agents: you plug in an AI SDK, configure the reasoning core, and then write everything else around it — monitoring, AIOps, orchestration, memory management.
This post is about memory management.
Imagine: you have six AI agents investigating a production incident. One finds OOMKilled in the logs — that’s the root cause. Another is simultaneously digging through Grafana, building its own theory about a CPU spike. A third pulls from Slack that there was a deployment yesterday. They’re all running in parallel, but none of them knows what the others found. The result: three competing hypotheses, two of which are garbage.
Our agents had no shared memory. So I built one.
What came out is a server that speaks the Redis protocol but has semantic search built in. Single binary, embeddings computed locally, any Redis client connects without modifications. No REST APIs, no external dependencies, no API keys.
Here’s the story of how I got there, why my attempt to fork Redis failed, and how Java code that was 2x slower than Redis ended up 1.36x faster.
Our Agents Had Amnesia
About six months ago, we were building an agent for investigating production incidents. The architecture is fairly standard for these systems: a Supervisor receives an alert, creates a plan via PlannerService, then fires off a batch of sub-agents in parallel using Promise.allSettled(). Each sub-agent goes to its own data source, digs up what it can, and then a Synthesizer assembles their findings into a final report.
Six sub-agents, each with its own MCP tool, its own scope, its own area of responsibility:
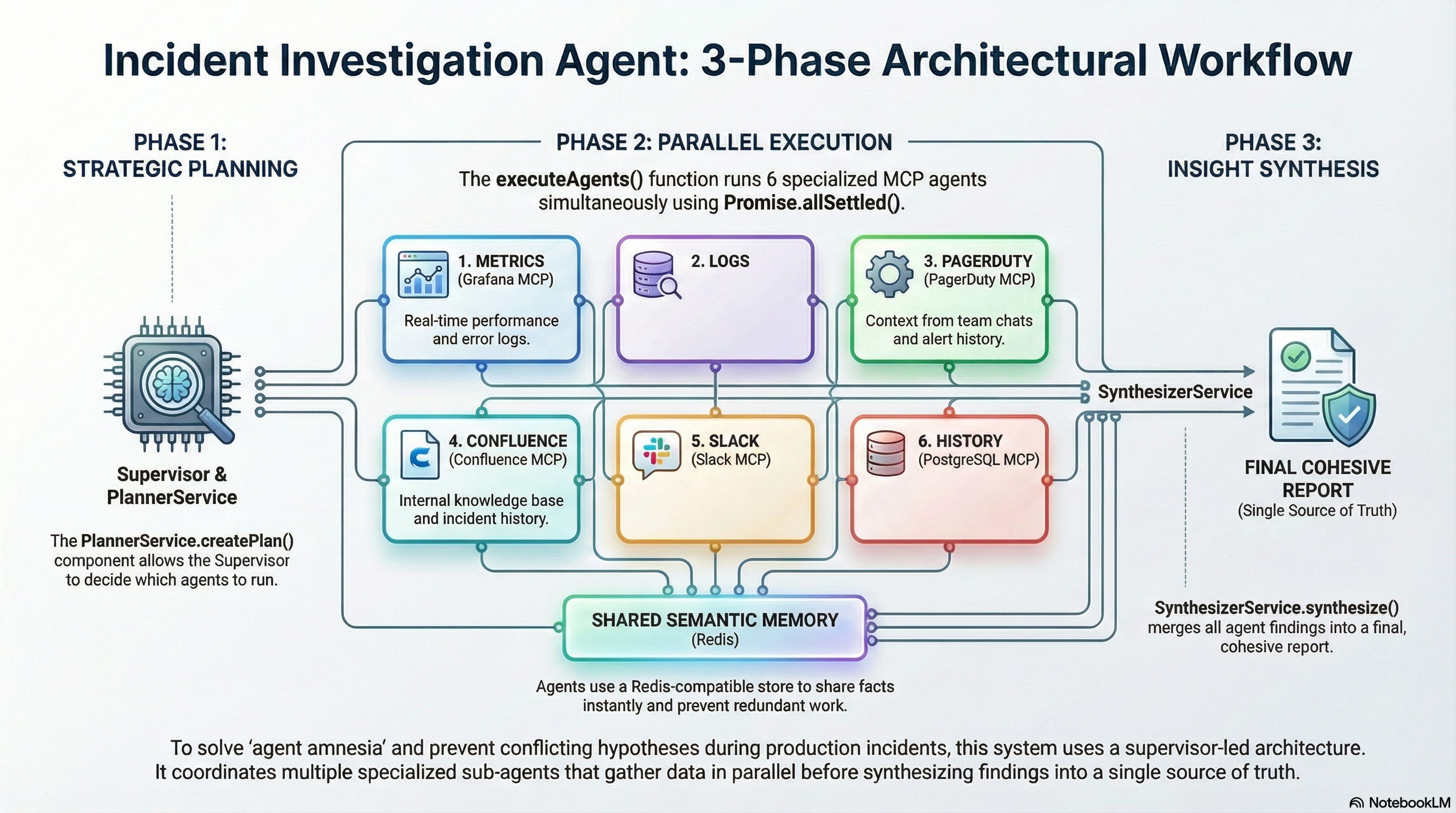
MetricsInvestigator dives into Grafana, LogsInvestigator into logs, SlackContextInvestigator into conversations, HistoryInvestigator into the database of past incidents. On paper — beautiful. Everything parallel, everything fast.
In practice — all six agents operated in complete isolation from each other.
LogsInvestigator finds OOMKilled on the payment-service pod. Great, that’s the root cause, case closed. But MetricsInvestigator has no clue — it’s busy in Grafana at the same time, sees a CPU spike, and diligently builds its own alternative theory. SlackContextInvestigator pulls out of the chat that a new version was deployed yesterday, but can’t connect it to the OOM because it doesn’t know about the OOM. In the end, Synthesizer receives three competing hypotheses, two of which are outright garbage. And sometimes outright hallucinations, because a single source of truth simply didn’t exist for the agents.
The first thing we tried was markdown files. The idea was dead simple: each agent writes its findings to a shared file, others read it. Sounds reasonable in theory, works terribly in practice. Race conditions on parallel writes, no structure, no semantic search, no TTL. That’s not memory — that’s a notebook six people are trying to fill in simultaneously with one pen.
It became obvious we needed working memory. Not a long-term RAG on OpenSearch that we already manage and curate for other tasks — but a fast shared context. One where an agent writes a fact, and milliseconds later another agent finds it by meaning. Essentially — like Redis, but with semantic understanding. And with that thought, I went to see what was out there.
What’s on the Market and Why Nothing Fit
The landscape of “agent memory” solutions looks reasonably mature at first glance: three main candidates, each with docs, SDKs, examples. But once you look at the architecture — the headaches begin.
Mem0 — positions itself as a “memory layer for AI agents.” Sounds exactly like what you need, until you start looking at what it’s made of. REST API, Python SDK. To get it running, you need Docker, Qdrant or Postgres for vector storage, and an API key from OpenAI or Cohere for embeddings. Let’s count: every MEMSAVE is an HTTP request to your server, which makes another HTTP request to OpenAI, waits for a vector, writes it to Qdrant. Three network hops to save a single fact. For working memory where milliseconds matter — that’s, to put it mildly, wasteful.
Zep — roughly the same story from a different angle. REST API, its own SDK, Postgres under the hood, embeddings via an external API. Plus the bonus of having to manage yet another database. As if we didn’t have enough of those.
Redis + Vector Search (Redis Stack) — now this is getting closer. Native RESP protocol, any client works. But vector search goes through the RediSearch module, and embeddings have to be computed externally and passed as ready-made vectors. Meaning you still spin up a separate service for inference, and every query gets an extra network call to the embedding API. Half a step to the goal, but half a step isn’t the goal.
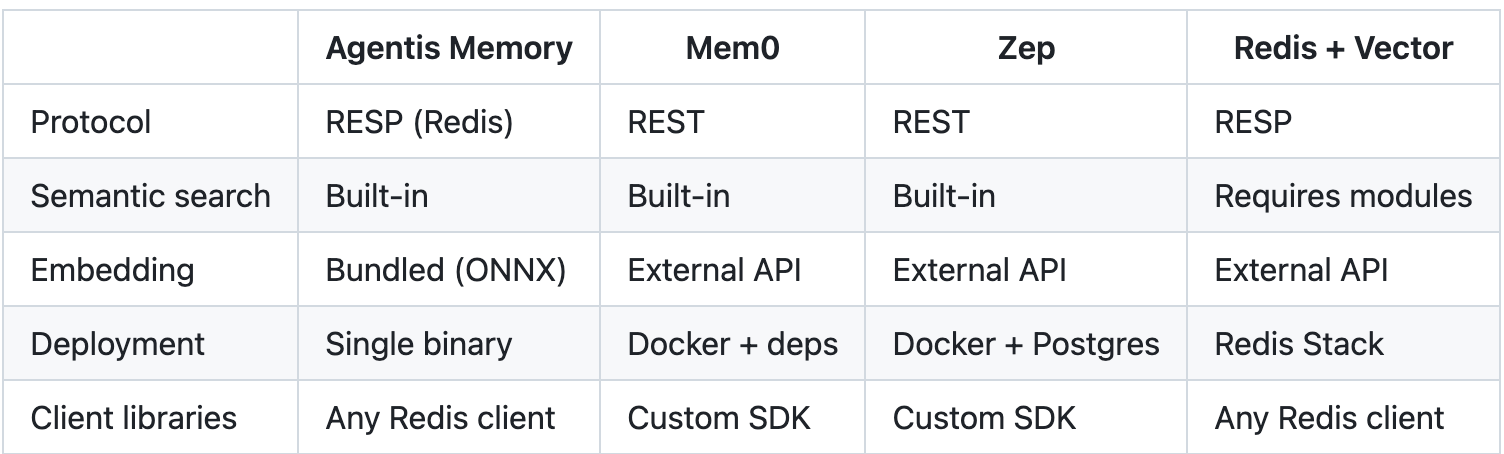
The core pain that united all these solutions — network and marshalling. I don’t need REST. I don’t need a custom SDK that I’ll then have to update and debug. I don’t need an API key from OpenAI to save the fact that “payment-service ran out of memory.” I want to do MEMSAVE key text and get +OK. That’s it. In one process, no network calls, no external dependencies. This is working memory, not bureaucracy.
Attempt Number One: Fork Redis
Okay, if nothing on the market fits — time to build it myself. And the first idea seemed obvious: take Redis, write a C module, embed ONNX Runtime right into it. Redis already handles KV, the protocol is there, production-tested, all that’s left is adding embeddings and an HNSW index. What could go wrong?
I tried. Everything went wrong.
Embedding ONNX Runtime into Redis’s C code is, let’s say, a peculiar kind of engineering pleasure. Manual memory management at the boundary of Redis’s allocator and ONNX, linking native libraries, debugging segfaults where Redis’s event loop meets ONNX’s inference thread. After a week I had a semi-working prototype that reliably crashed on concurrent requests, and a strong feeling that I was heading in the wrong direction.
I stopped and asked myself an honest question: why am I torturing myself with C when I’ve been writing Java for 12+ years?
The answer was uncomfortably simple — I’d somehow decided that a “real” Redis must be written in C. As if it were a law of nature. But if you think about it soberly: I don’t need a “real Redis.” I need a server that speaks the RESP protocol and can do embeddings. What it’s written in internally is beside the point. The user doesn’t care — they see redis-cli -p 6399 PING → PONG and that’s all that matters.
The Stack: GraalVM, G1, Java 25, and Incubator Toys
So, decision made — writing from scratch in Java. But not on the classic JVM. There’s an important nuance here.
GraalVM native-image compiles Java bytecode into an actual native binary. No JVM at startup, no JIT warmup, startup in milliseconds. The output is a single ~150MB file with the embedding model baked right in. Download, run, done. Exactly like Redis — no dependency juggling.
And since the project is internal anyway, not for sale, and nobody’s life depends on it in production — I decided to also take a few incubator technologies for a spin. When else would I get a chance to play with them on something real?
Java Vector API (Project Panama) — SIMD instructions straight from Java code, no JNI, no unsafe. Why does this matter here? Simple: the hottest operation in semantic search is computing cosine similarity between vectors. When MEMQUERY traverses the HNSW graph and calculates distance to the next node at every step — that’s exactly where SIMD gives a tangible boost. Not theoretical, but very measurable, as I’ll show below.
Project Loom (Virtual Threads) — lightweight threads that the Java runtime switches on its own, without OS-thread overhead. Each RESP connection lives in its own virtual thread. No event loop, no callbacks, no reactor pattern — you just write straightforward linear code, and the runtime handles concurrency. After years of reactive programming, this felt like a breath of fresh air.
ONNX Runtime — inference of the all-MiniLM-L6-v2 model right inside the server process. 384-dimensional vectors, inference ~2-5ms per chunk. No network calls, everything right here, in the same process.
jvector — a Java implementation of the HNSW graph for approximate nearest neighbor search. A mature library that fits well into the ecosystem.
The Story of How Performance Crashed, Then Soared
Now for the most interesting part — arguably the reason to keep reading.
The first version ran on a regular JVM. No Vector API, no native-image. Just Java, a ConcurrentHashMap, and ONNX Runtime through Java bindings. I ran memtier_benchmark, looked at the numbers, and... saw throughput that was 2x worse than Redis.
You know that feeling when you’ve been writing code for a week, you fire up a benchmark, and you want to quietly close your laptop and reconsider your life choices? That was it.
But instead of an existential crisis, I did two concrete things. First, I compiled everything through GraalVM native-image — eliminated JVM startup overhead, eliminated JIT warmup, got predictable performance from the very first second. Second, I rewrote the hot path for cosine similarity computation using the Vector API with explicit SIMD instructions.
The result: from 0.5x Redis to 1.36x Redis on string operations. From ~60K ops/sec to 168K. That moment when you realize Java can be fast — you just need to know where exactly it’s slow, and what to do about it.
How It Works
Internally, it’s fairly straightforward — one process, two engines that live side by side and share data:
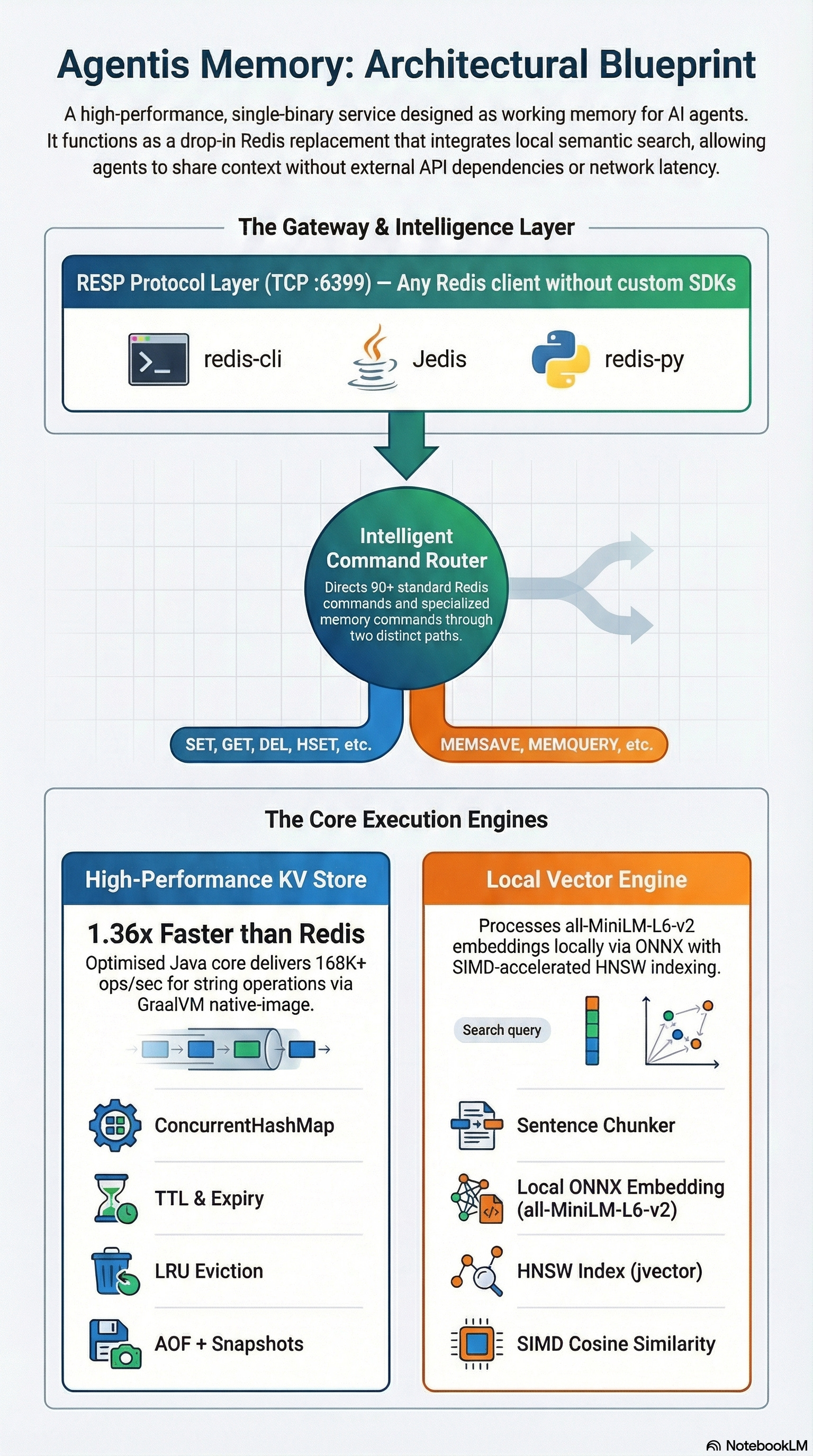
On the left — a classic KV store. 90+ standard Redis commands: strings, hashes, lists, sets, sorted sets, TTL, SCAN, even basic pub/sub. You can connect Redis Insight to port 6399 and everything looks exactly like regular Redis. Because from the client’s perspective, it is Redis.
But on top of that live four commands — the ones this whole thing was built for:
MEMSAVE — takes text, splits it into sentence-based chunks, runs each chunk through the ONNX model to get a 384-dimensional vector, and indexes the result in the HNSW graph. The KV write itself returns +OK immediately — all the heavy lifting with embeddings and indexing happens in the background, asynchronously. Typical latency from save to search-ready: 5-10ms per chunk.
redis-cli -p 6399 MEMSAVE "agent:fact:stack" "We use Python 3.12 with FastAPI"
# → OKMEMQUERY — semantic search. You phrase a query in natural language, the system vectorizes it and finds nearest neighbors in the HNSW graph by cosine similarity. Returns key, text, and score.
redis-cli -p 6399 MEMQUERY agent "what web framework do we use" 5
# → 1) 1) "agent:fact:stack"
# 2) "We use Python 3.12 with FastAPI"
# 3) "0.89"MEMSTATUS — indexing status of a specific key: indexed, pending, or error.
MEMDEL — deletes from both the KV store and the vector index simultaneously.
And here’s what I like most about this approach: no custom SDKs. Jedis, redis-py, ioredis, go-redis — grab whatever Redis client you already have in your dependencies and send MEMSAVE/MEMQUERY as regular custom commands via call() or execute_command():
import redis
r = redis.Redis(host='localhost', port=6399)
r.execute_command('MEMSAVE', 'agent:fact:1', 'Payment service hit OOM at 03:42 UTC')
results = r.execute_command('MEMQUERY', 'agent', 'memory issues', '5')For our incident investigation agent, this changed everything. LogsInvestigator finds the OOM — fires off a MEMSAVE. MetricsInvestigator, before going off to build its own theories, does a MEMQUERY and immediately sees: a colleague already found the root cause, no need to duplicate work, just supplement with metrics context. One source of truth, no hallucinations out of thin air.
Benchmarks: Honest Numbers
Note: Performance measurements were taken using memtier_benchmark, a tool from redis labs, on a separate Ubuntu server, not on the local machine, so the benchmark results are considered legitimate.
You can view the results here: https://scrobot.github.io/agentis-memory/benchmarks/report.html, or you can run them yourself.
Words and architecture diagrams are wonderful, but in our line of work you’re expected to show numbers. I ran memtier_benchmark against Redis 7.4, Dragonfly, and Lux. Standard configuration: 4 threads × 50 clients, 256-byte payloads. No tweaks.
Throughput (ops/sec)

On strings — 1.36x Redis. On mixed workload — 1.40x. Lux is faster (1.62x) — no illusions there. But Lux doesn’t have built-in vector search, and that’s a fundamental difference.
Latency p99 (ms)
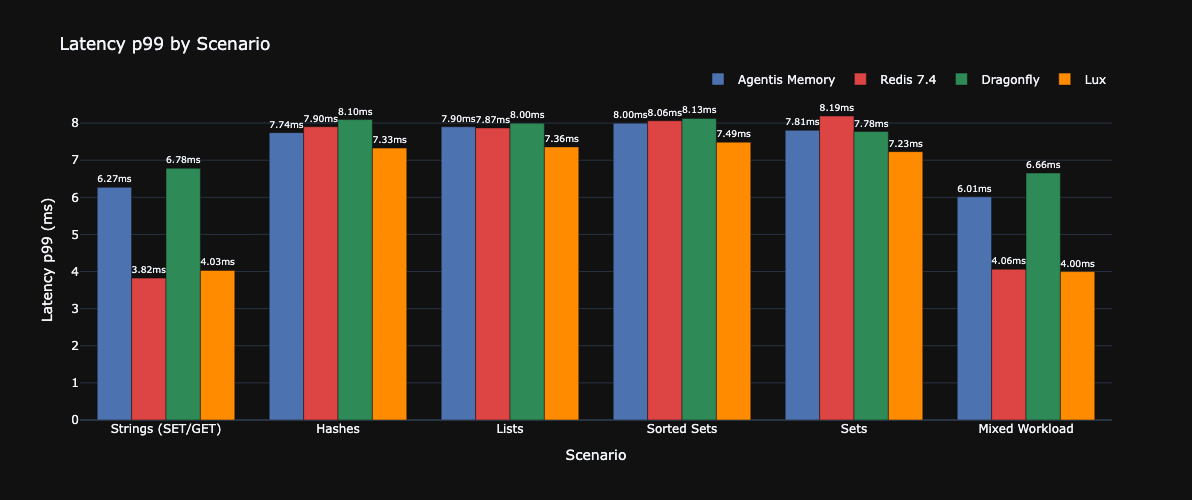
And here’s where honesty matters: p99 latency on strings is noticeably lower for Redis — 3.82ms vs our 6.27ms. That’s the price of garbage collection. GraalVM native-image minimizes GC pauses but doesn’t eliminate them entirely — and at the tail of the distribution, it shows. On hashes and sets — roughly on par with everyone.
Pipeline Scaling
This is where the picture gets truly interesting:
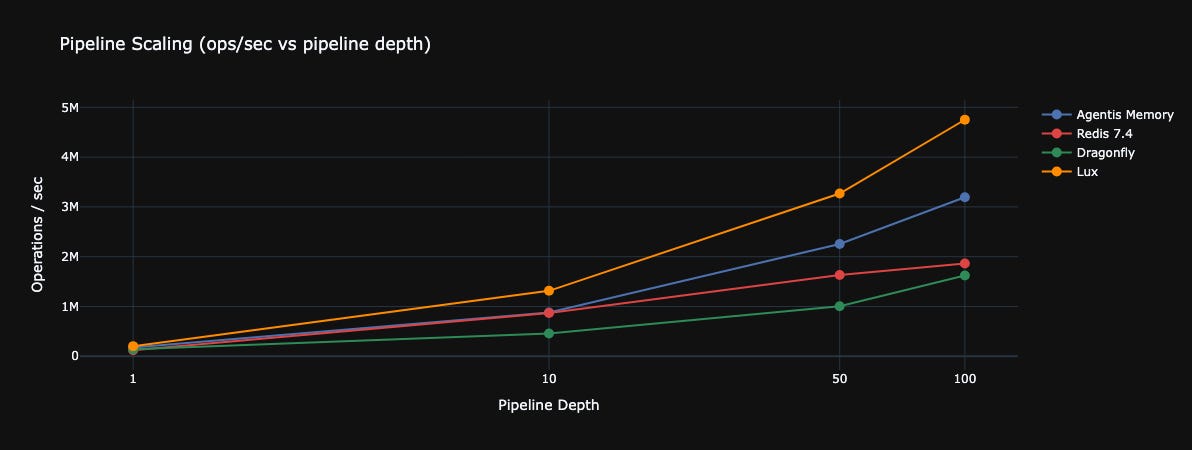
At pipeline depth 100 — 3.19 million ops/sec. That’s 1.71x Redis. This is where virtual threads and the absence of a single-threaded event loop start to shine: when requests come in batches, a multi-threaded architecture scales far better.
But I want to emphasize the key point: not a single competitor in this table can do MEMSAVE/MEMQUERY out of the box. Agentis Memory is the only one in this comparison that combines this level of KV performance with built-in semantic search in one process, with zero external dependencies.
Privacy-First: Why Embeddings Should Be Local
I want to say a few words about embeddings separately, because this isn’t just a technical decision — it’s a deliberate choice.
Our agents work with incident data. Logs, metrics, Slack conversations, PagerDuty alerts — all of this is sensitive information that can contain anything from customer names to internal infrastructure details. Send all of that to OpenAI just to get a vector? No thanks. Even if formally it’s “just embeddings” — why take the risk when you don’t have to?
all-MiniLM-L6-v2 runs via ONNX Runtime right inside the Agentis Memory process. No API keys, no network calls, no latency from external services, no dependency on someone else’s uptime. Inference takes ~2-5ms per chunk — faster than a single roundtrip to any cloud API.
And yes, it’s free. Zero dollars per embedding, even a million operations a day. For an internal tool that pushes thousands of facts through itself — that matters.
Instead of a Conclusion
AI technologies are replacing each other at a pace where you can barely blink. Model races, tool races, methodology races — even the development culture is changing faster than you can get used to it. And in this chaos, a lot of engineers are trying to make their own contribution to this new philosophy, to find their place.
I’ve been working with AI for almost five years now. I was lucky enough to try GitHub Copilot before it became available to everyone. Since then, I’ve been adapting AI in development, optimizing processes, and reinventing approaches — sometimes several times a month, because what worked yesterday is already obsolete tomorrow.
Agentis Memory is also an attempt to contribute to this shared endeavor. Of course, it’s not a silver bullet and it’s not perfection incarnate. You’re welcome to criticize it — and you should, I’ll be happy for constructive feedback. But this thing has already solved many of my problems: I have Claude Desktop, Claude Code, Codex, Antigravity, and Junie — all using shared memory through Agentis Memory. The quality of results has noticeably improved: agents understand what I want from them faster, make fewer mistakes, and don’t duplicate work.
I solved my problem. I hope I can help solve yours too.